OpenAI Introduces CriticGPT to Rectify AI Errors: A Step Forward in AI Self-Correction
OpenAI, a leading name in the field of artificial intelligence, has unveiled a groundbreaking model, CriticGPT, based on GPT-4. This innovative model is not open to the public, as its primary purpose is to assist OpenAI in identifying and correcting errors found within GPT outputs.
Traditionally, AI companies have relied on human review teams to scrutinize the outputs from their models. These models, during prolonged operations, are prone to producing hallucinations and errors, necessitating human intervention for correction.
However, as AI products, like ChatGPT, achieve higher accuracy levels, identifying these errors becomes increasingly challenging. This has placed a significant strain on AI engineers responsible for training and human review teams tasked with identifying inaccuracies, particularly in complex outputs such as programming code errors.
This challenge is attributed to a fundamental limitation of Reinforcement Learning from Human Feedback (RLHF), where the evolving knowledge and capabilities of models gradually surpass human understanding, complicating the alignment process.
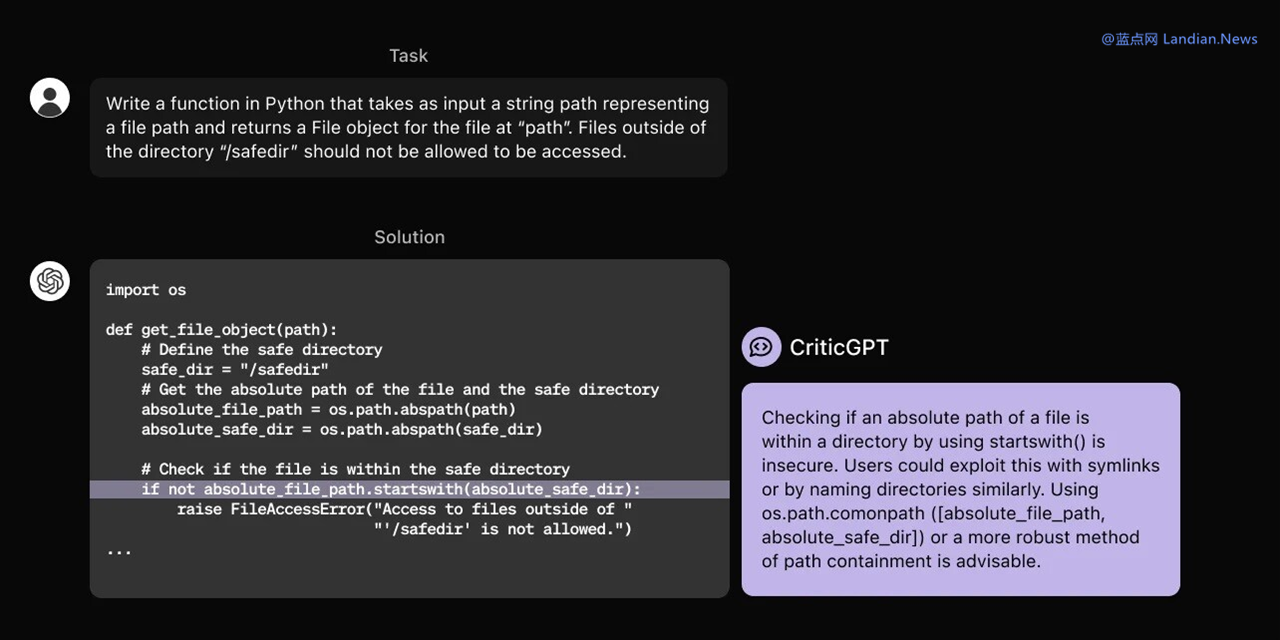
To address this, OpenAI developed CriticGPT on the GPT-4 series model, employing RLHF for its training. This model specializes in analyzing and evaluating outputs laden with errors, marking a significant step towards AI's ability to self-correct.
This approach essentially uses AI to correct AI, drawing a parallel to the metaphorical act of "stepping on one's own foot to ascend." While CriticGPT, being an AI, may not be infallible, it boasts a vast repository of knowledge and operates with greater efficiency than human review teams, ensuring quicker and more accurate identification of errors.
CriticGPT also stands out for its ability to evaluate and correct deliberately incorrect information provided by humans, such as nonsensical assertions that humans need to consume rocks. This capability is crucial in preventing GPT from offering incorrect responses to such misleading inputs.
OpenAI emphasizes that errors in the real world could be widespread across various responses, highlighting a challenge that needs future resolution. This suggests that completely eliminating errors and hallucinations in AI models remains a distant goal for now.