HuggingFace Unveils New System to Combat AI Model Cheating with NVIDIA Power
Renowned AI model hosting platform HuggingFace recently deployed a new system built with 300 NVIDIA H100 AI accelerators to test the capabilities of open-source and accessible artificial intelligence models. This round of testing, which included the MMLU-Pro among other AI model test sets, presents a notable step up in difficulty compared to previous datasets.
The platform noted that the datasets used in the past were too simplistic for the newly released models, comparing it to giving middle school exams to high school students, and thus, failed to accurately assess the models' capabilities.
Additionally, it was revealed that for marketing and promotional purposes, some models were found to have engaged in cheating by using optimized prompt words or assessment settings to give the models an unfair advantage, thereby achieving higher scores. This behavior is somewhat akin to how certain Android manufacturers manipulate their devices during benchmark tests to inflate their performance scores.
To counteract these issues, HuggingFace had earlier established the Open LLM Leaderboard, which assessed models under uniform conditions to collect results that users could replicate and compare in the real world.
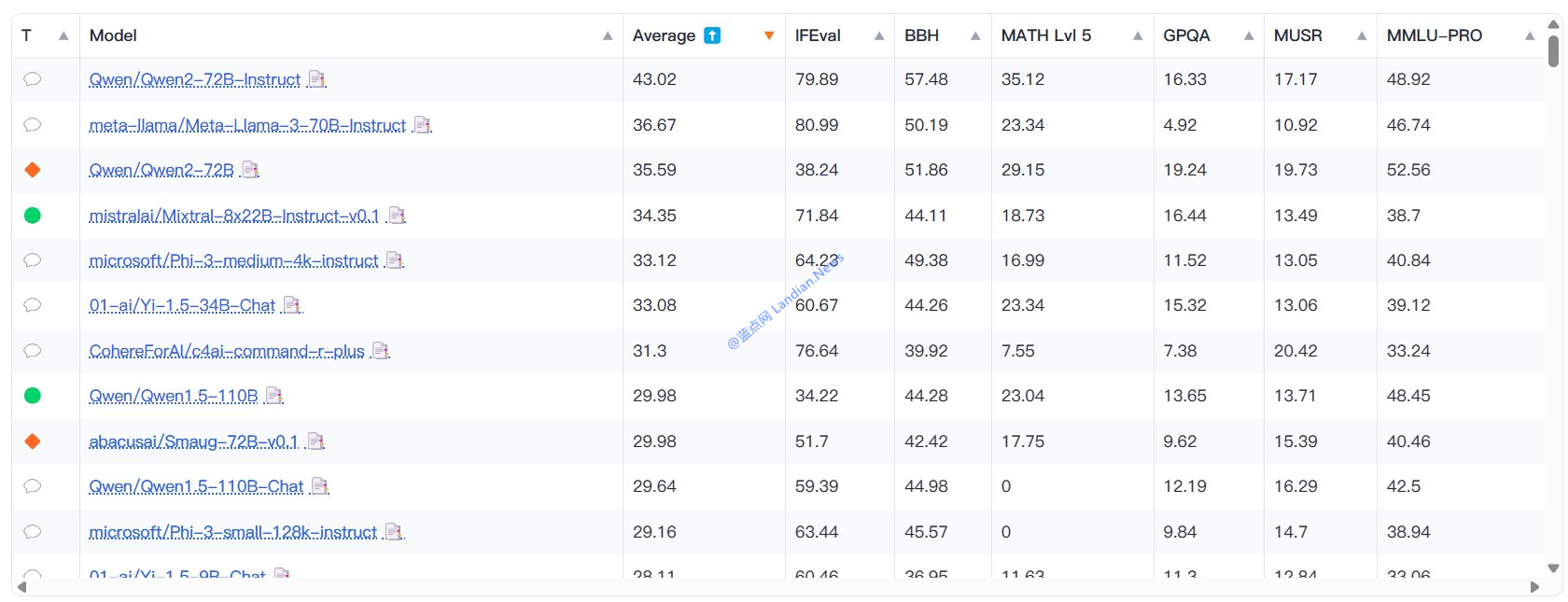
In pursuit of more genuine and effective evaluation outcomes, HuggingFace has introduced the Open LLM Leaderboard v2, reevaluating models with the 300 NVIDIA H100 accelerators and a new dataset.
In the latest test results, the Qwen series models by Alibaba Cloud surpassed the Meta Llama series to become the top-performing model, with the Qwen-72B model taking the lead.
Key highlights from this testing include:
- Model parameter size does not necessarily equate to better performance, indicating that some models with excessively large parameters did not perform as expected.
- The new evaluation successfully addressed the issue of previous tests being too easy, offering a more accurate reflection of current models' real-world abilities.
- There are indications that AI companies are now focusing primarily on benchmark tests, potentially neglecting other performance aspects.
This marks the first time in the AI industry that cheating in tests has been explicitly mentioned, suggesting that some developers might focus on optimizing for benchmark tests to achieve better scores—a practice that is viewed negatively. However, given the vast number of AI companies vying for attention for promotional or fundraising purposes, optimizing scores seems to be a strategy some are willing to employ.
Beyond conventional cheating methods (such as the use of optimized prompts and test settings mentioned earlier), these benchmark test optimizations are difficult to detect, suggesting that the industry may need to invest more time in creating unique test sets to evaluate models more accurately.
![[Online Tool] Clay Filter AI – Quickly Convert Your Photos into Clay Animation Style (Free)](https://img.lancdn.co/news/2024/05/2049T.png)