Alibaba Cloud's Qwen team open-sources two voice base models with better speech recognition performance than OpenAI Whisper model
Alibaba Cloud's Qwen team recently open-sourced two speech base models on Github, SenseVoice and CosyVoice, with the former designed for speech recognition and the latter for speech generation. These models demonstrate exceptional performance, with SenseVoice outperforming OpenAI's Whisper model in recognition accuracy.
These models are fully open-sourced under the Apache 2.0 license, allowing individuals, developers, and enterprises to download and use the models for free, offering an alternative to paid API models like Whisper.
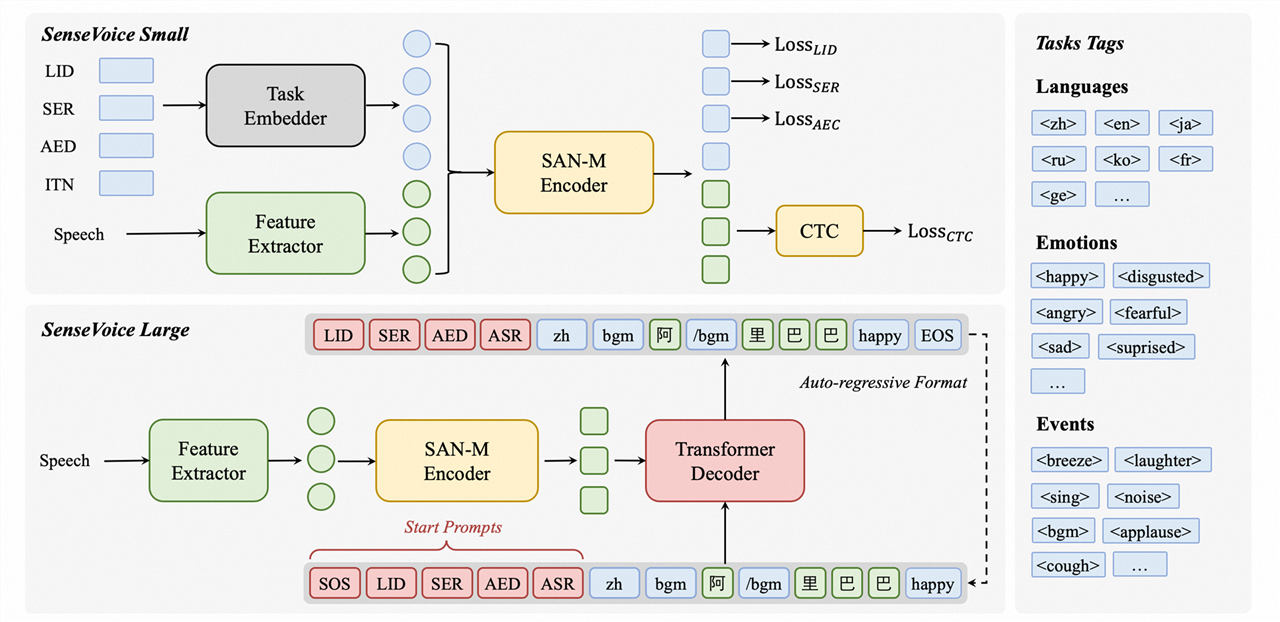
SenseVoice Model:
SenseVoice is a multilingual audio understanding model supporting speech recognition, language identification, speech emotion recognition, acoustic event detection, and inverse text normalization. The model was trained using hundreds of thousands of hours of labeled audio to ensure its universal recognition capability. It can be applied to recognize Mandarin, Cantonese, English, Japanese, and Korean audio and produce rich text transcriptions with emotional and event annotations.
- Multilingual Recognition: Trained with over 400,000 hours of data, supporting more than 50 languages, and surpassing the Whisper model in recognition accuracy.
- Rich Text Recognition: Features excellent emotion recognition capabilities, achieving and exceeding the results of the current best emotion recognition models on test data.
- Sound Event Detection: Capable of detecting a variety of common human-computer interaction events, including music, applause, laughter, crying, coughing, and sneezing.
- Efficient Inference: The SenseVoice-Small model uses a non-autoregressive end-to-end framework with extremely low inference latency, processing 10s of audio in just 70ms, 15 times faster than Whisper-Large.
- Fine-tuning and Customization: Offers convenient fine-tuning scripts and strategies for users to address long-tail sample issues based on business scenarios.
- Service Deployment: Features a complete service deployment chain, supporting multi-concurrent requests, with client-side language support for Python, C++, HTML, Java, and C#.
CosyVoice Model:
CosyVoice also supports multilingualism, timbre, and emotional control, excelling in multilingual voice, zero-shot voice generation, cross-language voice cloning, and command following capabilities.
Both models are part of the FunAudioLLM series, a framework aimed at enhancing natural speech interactions between humans and large language models to enable applications like speech translation, emotional voice chat, interactive blogging, and expressive audiobook narration, pushing the boundaries of speech interaction technology.
These models are now available on the Modelscope and HuggingFace platforms for interested developers to download and test.
- SenseVoice Model: https://github.com/FunAudioLLM/SenseVoice
- CosyVoice Model: https://github.com/FunAudioLLM/CosyVoice
For a complete description of FunAudioLLM: https://fun-audio-llm.github.io/

![[Online Tool] Clay Filter AI – Quickly Convert Your Photos into Clay Animation Style (Free)](https://img.lancdn.co/news/2024/05/2049T.png)