Microsoft Unleashes GraphRAG: Elevating AI Response Precision with Graph-Based Retrieval
In the early part of this year, Microsoft launched GraphRAG — a graph-based Retrieval-Augmented Generation (RAG) method capable of answering questions on private or previously unseen datasets. This method surpasses traditional RAG techniques in structuring information retrieval and generating comprehensive responses, significantly improving the accuracy of AI responses.

Today, Microsoft announced that GraphRAG has been made open source on Github. The GraphRAG repository also includes a solution accelerator, offering a simple and accessible API experience. This API has been hosted on Azure, allowing developers to deploy it with just a few clicks without the need to write any code.
GraphRAG utilizes large language models to automatically extract rich knowledge graphs from any collection of text documents. One of its unique features is the ability to report the semantic structure of data before a user query.
It then detects densely connected node communities in a hierarchical manner, dividing the graph into multiple levels from high-level to low-level topics. Using LLM to summarize these node communities creates hierarchical summaries of data and provides an overview of datasets without needing to know the questions in advance.
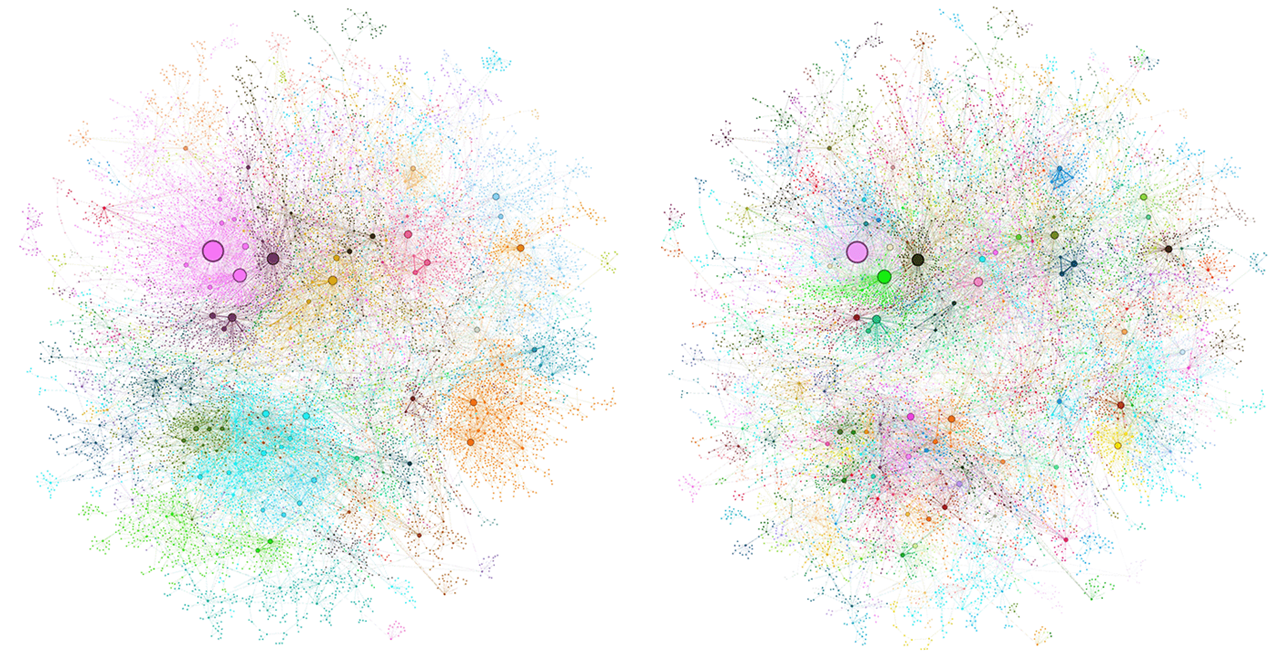
Different colors in the above figure represent different node communities; the left figure shows level 0 communities representing the highest priority topics, while the right figure shows level 1 communities displaying subtopics.
Advantages of community summaries for global questions:
Microsoft recently published a paper detailing how community summaries can aid in answering global questions, which often involve the entire dataset rather than focusing on specific text blocks.
In such scenarios, simple RAG methods based on vector search are insufficient. For instance, when considering the main topics within a dataset, simple RAG methods often provide incorrect answers because they generate responses from text blocks semantically similar to the query, not necessarily the subset of input texts needed to answer the question.
However, if a question involves the entire dataset, all input texts should be considered. Since simple RAG methods only consider the most similar top k input text blocks, this approach can be problematic.
Worse still, simple RAG methods might match the question with text blocks that seem similar on the surface, leading to misleading answers instead of the correct content.
Community summaries help answer such global questions because the graph index of entities and relationship descriptions considers all input texts during its construction. Thus, one can use the map-reduce method for question answering, retaining all content relevant to the data background.
With the open-sourcing of GraphRAG, all developers and businesses can access the project on Github and develop or improve their projects based on it. This not only provides the developer community with a powerful tool but also introduces a new and unique RAG method to the field of information retrieval and response generation.
Interested developers can view the paper here: Microsoft Research Paper
Project address: Github - Microsoft GraphRAG